مهمانان این پیشنشست آقایان ایمان تهمتن (دانشجوی دکتری دپارتمان علم اطلاعات دانشگاه تنسی ناکسویل آمریکا)، علیرضا انتهایی (دانشجوی دکتری علم اطلاعات و دانششناسی دانشگاه تهران و مدیر کل فراهمآوری و پردازش منابع دیجیتال سازمان اسناد و کتابخانه ملی ایران) و سید ابوالحسن نظامدوست (مدیر نرمافزار دفتر تبلیغات اسلامی) بودند.
در ابتدا، دبیر نشست، اعظم نجفقلینژاد، عضو هیئتعلمی سازمان اسناد و کتابخانه ملی ایران به معرفی موضوع پیشنشست پرداختند و گزارش مختصری از پیشنشست اول را بیان نمودند و این پیشنشستها را در جهت افزایش غنای نشست اصلی کنگره عنوان نمودند و خواستار تعامل حداکثری حاضران در جلسه شدند. ایشان ابتدا به بیان مقدماتی دربارۀ افزایش حجم عظیم دادهها در شبکههای اجتماعی و سیستمهای اطلاعاتی توسط افراد و سازمانها پرداختند و به زبان ساده بیگدیتا، دادههای بزرگ یا دادههای کلان را تبیین کردند و معمای کلان دادهها را در احساس غرقشدگی سازمانها در دادههای بزرگ عنوان نمودند. ایشان در این زمینه به پژوهش MIT بر روی 3000 مدیر اشاره نموده و بیان داشتند 60 درصد مدیران این احساس غرقشدگی در دادههای بزرگ را تأیید نمودند و بر اهمیت تحلیل دادهها و کیفیت دادهها در جهت بهبود عملکرد سازمانها پرداختند. دکتر نجفقلینژاد در ادامه به مشخصههای اصلی بیگ دیتا و مدلها 3V، 4V و5V اشاره کرده و حجم، تنوع، سرعت، صحت و ارزش دادهها را بهعنوان مشخصههای اصلی دادههای کلان گزارش نمودند. کهکشان داده و کاربرد این دادههای بزرگ و اهمیت سرعت تحلیل دادهها در عرصۀ رقابت کنونی از دیگر مباحث مطرح بود. ایشان به اهمیت سرعت تحلیل دادهها در مسائل پزشکی از جمله کووید 19 اشاره نموده و سرعت تحلیل دادهها و کشف واکسن را بهعنوان مزیت رقابتی برای کشورها عنوان کردند. در ادامه اهمیت تحلیل دادهها در مسائل بهداشتی، آموزشی، رابطه بین بازیهای رایانهای و میزان جرم و جنایت، تحلیل دادههای تصادفات جادهای برای جلوگیری از مرگومیر و … مورد تحلیل قرار گرفت. در پایان وضعیت شرکتهای بزرگ جهان در بهرهگیری از دادههای کلان موردبحث واقع شد و به شرکتهای والمارت، نتفلیکس، ایبی، پی. اند جی؛ و اوبر بهعنوان بزرگترین شرکتهای پیشرو در بهرهگیری از تحلیل دادههای کلان اشاره شد. SNA یا تجزیهوتحلیل شبکههای اجتماعی بهعنوان یکی از نمودهای تولید دادههای کلان در بحث بازاریابی هدفمند پایانبخش صحبتهای ایشان بود.
در ادامه آقای ایمان تهمتن سخنرانی خود را با موضوع کاربردهای بیگ دیتا در زمینههای مختلف و خصوصاً در حوزۀ سازمانها و کتابخانههای غیر ایرانی آغاز کردند. ایشان ابتدا به میزان حجم تولید دادهها در هر دقیقه توسط فناوریهای مختلف از جمله شبکههای اجتماعی اشاره کردند و به کاربرد این دادهها تأکید کردند. سیستم بانکداری، سلامت، آموزش، دولتها، حملونقل، بیمه و … از حوزههایی است که از تحلیل دادههای کلان میتوانند استفاده کنند. ایشان در ادامه به EHR یا همان Electronic Health Records (پرونده الکترونیکی بیماران) اشاره کرده و آن را در کشور آمریکا و فرانسه تحلیل کردند. با تحلیل دادههای سلامت در فرانسه، بیمارستانها تعداد پرسنل و پرستاران را بر مبنای تعداد بیمار پیشبینی نمودند. از دیگر عرصههای استفاده از تحلیل دادههای EHR، پیشبینی بیماران در معرض خطر ابتلا به بیماریهای مختلف از جمله سرطان و پیشبینی بیماریهای مزمن با تحلیل دادههای سلامت است. آقای تهمتن در ادامه به کشور تایوان اشاره کردند، این کشور قبل از اعلام سازمان بهداشت جهانی به پاندمیک بودن ویروس کووید 19، به تحلیل دادههای مسافرت شهروندان تایوانی در شروع بیماری کووید در این کشور پرداخت و افراد دارای ریسک بالا را در قرنطینه نگه داشت و با برنامههای هدفمند این کشور صرفاً 10 فوتی را در اثر کووید 19 تجربه کرد.
ایشان در ادامه به مطالعه ده کتابخانه عمومی در امریکا و تحلیل دادههای آنها اشاره کردند. تعداد کاربران این ده کتابخانه به 8 میلیون کاربر میرسید و اهدافی نظیر شناخت گروههای مختلف کاربران از نظر سن، جنس، نژاد و …، حفظ کاربران فعلی و جذب کاربران جدید دنبال میشود. نتیجه اصلی این مطالعه نشان داد تنوع کاربران مانع ارائه الگوهای یک شکل در بین کتابخانههای یک کشور میشود. این نتیجه حاصل نمیشد مگر در سایه تحلیل دادههای بزرگی که از این ده کتابخانه حاصل شد. ایشان در ادامه به استفاده از دادههای شبکههای اجتماعی از جمله فیسبوک در تحلیل دادههای انتخابات ریاست جمهوری آمریکا در سال 2016 اشاره کرد که با تحلیل دادهها، کاندیدای ریاست جمهوری با سرمایهگذاری بر اساس دادههای حاصل از مردم، موفقیت خود را رقم زد. ایشان به پژوهش دیگری دربارۀ شناسایی جوامع حامی داعش از طریق تحلیل دادهها پرداختند. نتیجه این تحلیل نشان داد بسیاری از داعشیها دیدگاههای افراطی خود را از پژوهشگران مسلمانی که تفکر داعشی دارند، اخذ میکنند.
دومین سخنران این نشست آقای علیرضا انتهایی به جایگاه متخصصان علم اطلاعات و دانشگاههای مربوطه و سازمانهای تخصصی در بحث داده پرداختند و بحث متادیتا را در این زمینه مهم شمردند و نقش متخصصان علم اطلاعات را بهعنوان سؤال بحث، مطرح کردند. ایشان در ادامه به دادههای پرت در بین دادهها اشاره کرده و استفاده از این دادهها را عامل تولید اطلاعات غلط عنوان کردند. بحث حکمرانی داده و کیفیت داده در سطح کلان از دیگر مباحث مطرح بود. ایشان به موجهای علم داده و متخصصان درگیر در آن اشاره داشتند. موج اول بیشتر متخصصان ریاضی و موج دوم بینرشتهای شدن متخصصان علم داده را در برداشت. ایشان به نقش گروههای آکادمیک اشاره نموده و تجدیدنظر در سرفصلهای آموزشی را ضروری دانستند. آقای انتهایی به ابهام در نقشهای مرتبط با کار با دادهها و به آشنا بودن متخصصان علم اطلاعات با بحث داده و استانداردهای فرادادهای از جمله مارک و دوبلینکور بهعنوان گامهای اولیه اشاره کردند و اذعان داشتند متخصصان علم اطلاعات بر سازماندهی داده واقف هستند.
آقای انتهایی به نقشهای متخصصان علم اطلاعات مرتبط با داده اشاره کردند: مهارتهای بین فردی و ویژگیهای رفتاری، دانش زمینهای، دانش و مهارتهای تخصصی دادهها، فناوری اطلاعات، آموزش و مشاوره و کار گروهی از جمله این مهارتها است. ایشان بهصورت جزئی به ویژگیهای هرکدام از این مهارتها اشاره کردند و بر دانش و مهارتهای تخصصی دادهها تأکید کردند و به درک جنس انواع دادهها، شناخت کلان دادهها، دانش و مهارتهای مربوط به اشتراکگذاری دادهها، دادههای پیوندی، چرخۀ عمر مدیریت دادهها، آگاهی از چارچوبهای حکمرانی داده، دادهکاوی، دیجیتالسازی، دانش و مهارت استفاده از فرادادهها، پالایش و تمیز کردن دادهها و … تأکید داشتند.
در پایان ایشان به معرفی و اهمیت آشنایی متخصصان علوم اطلاعات با ابزارهای مدیریت فرادادهها از جمله MARC EDIT، OPENREFINE برای پالایش، تمیزسازی و بهبود کیفیت دادهها و TABLEAU برای مصورسازی و تحلیل دادهها پرداختند.
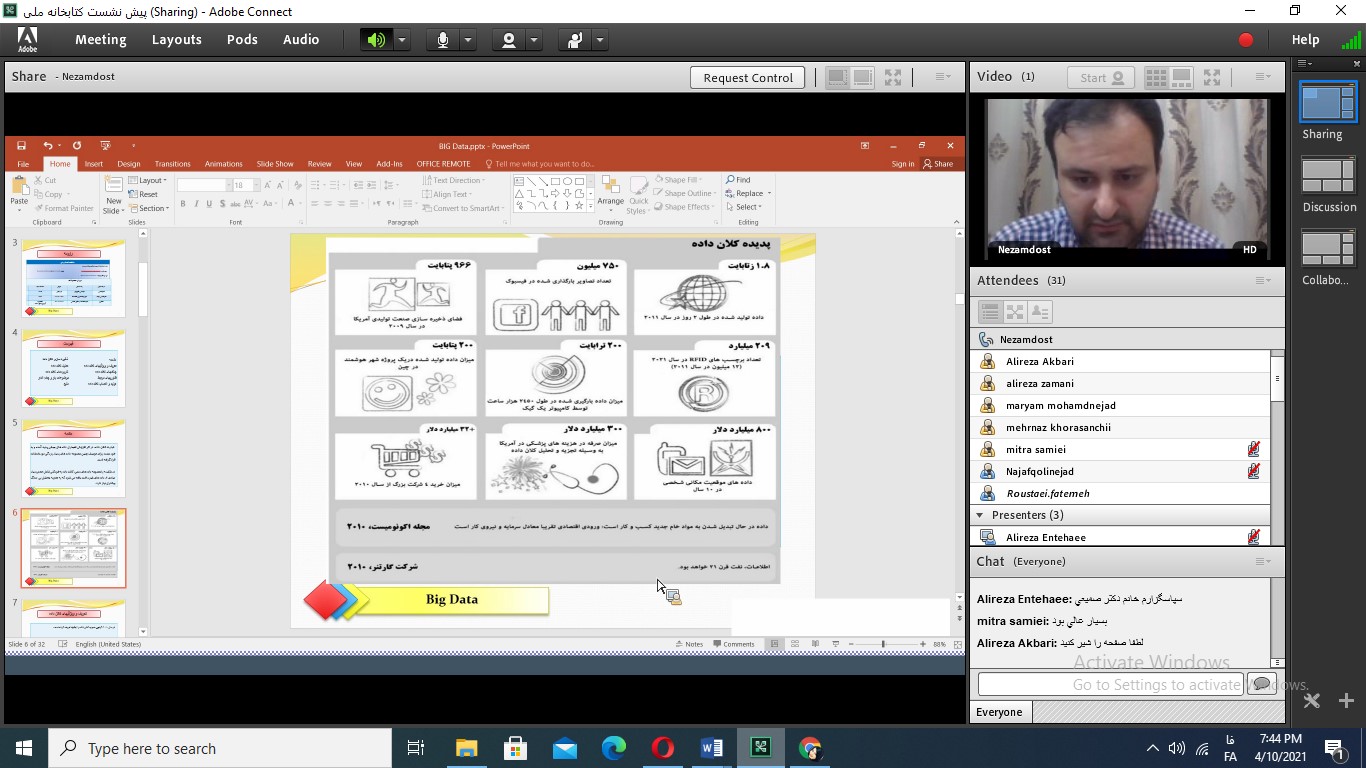
آخرین سخنران این نشست آقای سیدابوالحسن نظامدوست به مقدماتی دربارۀ پدیده کلان دادهها اشاره و به تعاریف و ویژگیهای کلان دادهها پرداختند. مدلهای کلان دادهها از دیگر مباحث مطرح بود. ایشان به چالشهای کلان دادهها اشاره کردند و به بحث دربارۀ موانعی پرداختند که در توسعه کاربردهای کلان داده باید بر آنها غلبه شود. برخی از این چالشها عبارت بود از: بحث نمایش داده، کاهش افزونگی و فشردهسازی دادهها، مدیریت چرخه حیات داده، سازوکارهای تجزیهوتحلیل، مدیریت انرژی، گسترشپذیری و مقیاسپذیری و … فناوریهای مرتبط با کلان دادهها از جمله رایانش ابری، اینترنت اشیاء، دیتاسنترها یا مرکز داده و هدوپ از دیگر مباحث مطرح در این نشست بود. ایشان به زنجیرۀ ارزش کلان دادهها در 4 مرحله تولید داده، اکتساب داده، ذخیرهسازی داده و تحلیل داده اشاره کردند و در مورد هر مرحله بحث کردند. آقای نظامدوست درباره کاربردهای کلان داده هم صحبت کردند و در پایان موضوعات باز و چشمانداز موجود دربارۀ این مباحث جدید را مورد تحلیل قرار دادند.
پایانبخش این نشست گفتگو و بحث حاضران در جلسه دربارۀ مباحث مطرح بود.
گزارش: دکتر نجفقلینژاد
دبیر پنل تخصصی کتابخانه ملی در کنگره ششم متخصصان علوم اطلاعات
فیلم کامل این نشست در آدرس زیر قابل دسترسی علاقمندان است:
http://learning.ilisa.ir/pn6ertd0nb2j